# MicroExpression_Classification
**Repository Path**: sunmingqiyyds/MicroExpression_Classification
## Basic Information
- **Project Name**: MicroExpression_Classification
- **Description**: 基于ResNet50网络对casme2实现微表情分类模型的训练和安卓端部署
- **Primary Language**: Python
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 2
- **Created**: 2023-08-15
- **Last Updated**: 2023-08-15
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# 0 项目简介
> 您是否有过以下困惑:
1. > 第一次约会中,内心小鹿乱撞,却摸不清他(她)对我的真实情感,是喜欢、犹豫还是......我应该怎么做,才能得到他(她)的真心呢?
1. > 青春期的孩子最为敏感,最为复杂,为人父母,管教过于温和怕起不到效果,过于激烈又会伤了孩子的自尊心,探寻他们内心深处的真实情感,才能对症下药。
> 现在,只需要fork本项目,安装一个微表情识别软件的手机,就能为你解决以上困惑,为你追求真爱,为你家庭和睦助上一臂之力。
- 任务:本次实验是一个图像多分类问题,利用ResNet50卷积神经网络实现微表情分类,再部署至手机端。
- 实践平台:百度AI实训平台-AI Studio、Python3.7+ Paddle2.2、Android Studio、安卓手机。
该项目是本人为完成学校课程而创建的,数据集不能公开,在此深表歉意。
但模型文件(MicroExpression.nb)文件有,文件在我的AI Studio[微表情](https://aistudio.baidu.com/aistudio/projectdetail/3425078?contributionType=1) 中,需要的朋友拿去手机端部署就ok,部署直接看[第五版块](#_5基于Paddle-Lite进行安卓部署)。
针对此项目还存在的改进空间,以及这类场景在飞桨框架下的实现,希望大家多交流观点,fork优化,相互关注,共同学习进步[个人主页](https://aistudio.baidu.com/aistudio/usercenter)。
# 1 数据集介绍
人类接触外界的过程通常伴随一系列复杂的心理活动,由此诱发情感,也称情绪。研究表明,情绪变化会在脸部产生表情,两者存在绝对的对应关系。
近年来,在人脸表情范畴下,新兴起一个细化的分支——微表情( Micro-Expression)。
* 猜猜左边这位大哥的微表情,看似一脸认真,其实他的标签是高兴哈哈哈哈哈
* 仔细观察右边这位小姐姐,眉头微微皱起,嘴角轻轻上扬,如此迷惑,其实她代表微表情的是压抑
由此可见,未经正规训练过的人很难识别微表情所代表的真实情感。
不同于传统的宏观表情,微表情具有如下特点:
1. 真实的情绪,复杂心理活动
1. 非自主控制,不自觉流露
1. 持续时间短,强度弱,不易察觉
其实,微表情研究在侦察讯问、安全司法、临床医学都有很好的应用前景,因此开发一套自动化设备,对微表情进行识别研究是很有必要的。
微表情来源于中科院提供的CASMEII数据库,这些样本主要包括七类:高兴、惊讶、恐惧、悲伤、厌恶、压抑和其他。
由于样本量较少,因此训练集、验证集、测试集按照6:2:2划分。
训练样本量| 2,464张
验证样本量| 822张
测试样本量| 826张
加载使用方式|自定义数据集
## 1.1 数据标注
数据集分为train、valid、test三个文件夹,每个文件夹内包含7个分类文件夹,每个分类文件夹内是具体的样本图片。
```python
!unzip data/data128555/Classification2.zip
```
```python
import io
import os
from PIL import Image
from config import get
# 数据集根目录
DATA_ROOT = 'classification2'
# 标签List
LABEL_MAP = get('LABEL_MAP')
# 标注生成函数
def generate_annotation(mode):
# 建立标注文件
with open('{}/{}.txt'.format(DATA_ROOT, mode), 'w') as f:
# 对应每个用途的数据文件夹,train/valid/test
train_dir = '{}/{}'.format(DATA_ROOT, mode)
# 遍历文件夹,获取里面的分类文件夹
for path in os.listdir(train_dir):
# 标签对应的数字索引,实际标注的时候直接使用数字索引
label_index = LABEL_MAP.index(path)
# 图像样本所在的路径
image_path = '{}/{}'.format(train_dir, path)
# 遍历所有图像
for image in os.listdir(image_path):
# 图像完整路径和名称
image_file = '{}/{}'.format(image_path, image)
try:
# 验证图片格式是否ok
with open(image_file, 'rb') as f_img:
image = Image.open(io.BytesIO(f_img.read()))
image.load()
if image.mode == 'RGB':
f.write('{}\t{}\n'.format(image_file, label_index))
except:
continue
generate_annotation('train') # 生成训练集标注文件
generate_annotation('valid') # 生成验证集标注文件
generate_annotation('test') # 生成测试集标注文件
```
## 1.2 数据集定义
接下来我们使用标注好的文件进行数据集类的定义,方便后续模型训练使用。
### 1.2.1 导入数据集的定义实现
```python
import paddle
import numpy as np
from config import get
paddle.__version__
```
```python
from dataset import MicroExpression
```
### 1.2.2 实例化数据集类
根据所使用的数据集需求实例化数据集类,并查看总样本量。
```python
train_dataset = MicroExpression(mode='train')
valid_dataset = MicroExpression(mode='valid')
print('训练数据集:{}张;验证数据集:{}张'.format(len(train_dataset), len(valid_dataset)))
```
# 2 模型选择和开发
本次我们使用ResNet50网络来完成我们的案例实践。
## 2.1 模型的介绍
以下项目对于ResNet50结构、功能有详细介绍,故在此不赘述,感兴趣的读者可以点击链接详细了解。
[https://aistudio.baidu.com/aistudio/projectdetail/3405244?contributionType=1](http://)
## 2.2 模型的选择
```python
network = paddle.vision.models.resnet50(num_classes=get('num_classes'), pretrained=True)
```
```
model = paddle.Model(network)
model.summary((-1, ) + tuple(get('image_shape')))
```
# 3 模型训练和优化
其中关键API介绍如下:
##### CosineAnnealingDecay:
[https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/lr/CosineAnnealingDecay_cn.html#cosineannealingdecay](http://)
##### Momentum:
[https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/Momentum_cn.html#momentum](http://)
## 3.1 模型配置
```python
EPOCHS = get('epochs')
BATCH_SIZE = get('batch_size')
def create_optim(parameters):
step_each_epoch = get('total_images') // get('batch_size')
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=get('LEARNING_RATE.params.lr'),
T_max=step_each_epoch * EPOCHS)
return paddle.optimizer.Momentum(learning_rate=lr,
parameters=parameters,
weight_decay=paddle.regularizer.L2Decay(get('OPTIMIZER.regularizer.factor'))) #正则化来提升精度
# 模型训练配置
model.prepare(create_optim(network.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy(topk=(1, 5))) # 评估指标
# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
```
## 3.2 模型的训练
```python
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
valid_dataset, # 评估数据集
epochs=EPOCHS, # 总的训练轮次
batch_size=BATCH_SIZE, # 批次计算的样本量大小
shuffle=True, # 是否打乱样本集
verbose=1, # 日志展示格式
save_dir='./chk_points/', # 分阶段的训练模型存储路径
callbacks=[visualdl]) # 回调函数使用
```
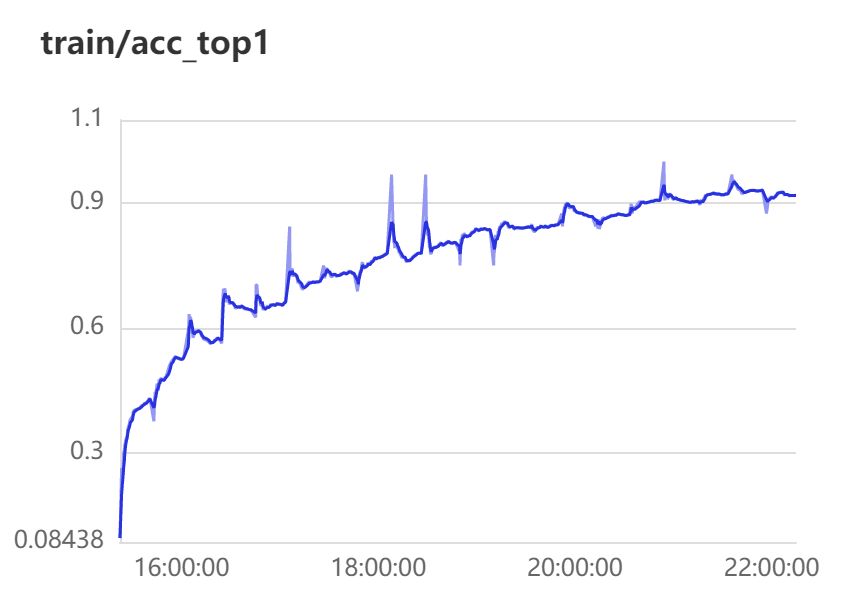
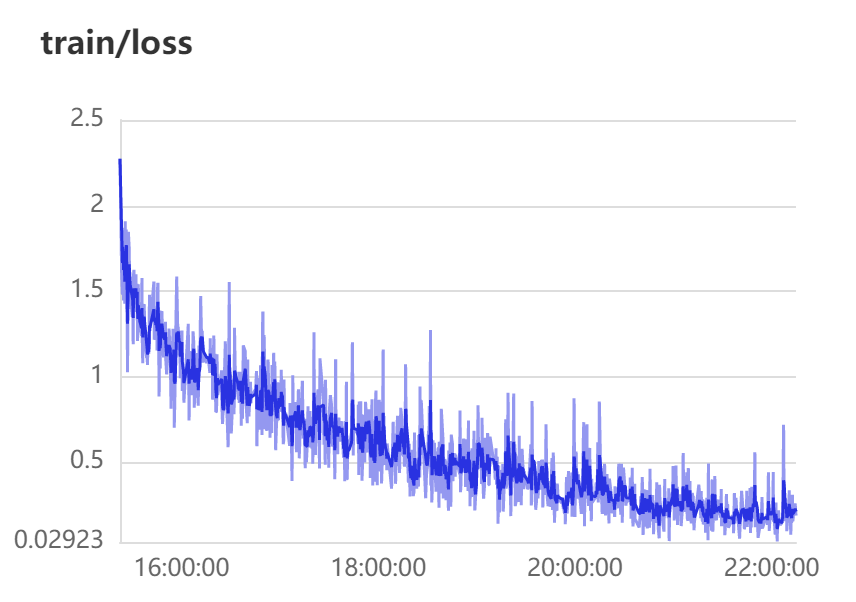
top1 表示预测的第一个答案就是正确答案的准确率
top5 表示预测里面前五个包含正确答案的准确率
预测可视化:
## 3.3 模型的保存
```python
model.save(get('model_save_dir'))
```
# 4 模型评估和测试
## 4.1 测试数据集
```python
# 模型评估和测试
predict_dataset = MicroExpression(mode='test')
print('测试数据集样本量:{}'.format(len(predict_dataset)))
```
## 4.2 执行预测
```python
from paddle.static import InputSpec
# 网络结构示例化
network = paddle.vision.models.resnet50(num_classes=get('num_classes'))
# 模型封装
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1] + get('image_shape'), dtype='float32', name='image')])
# 训练好的模型加载
model_2.load(get('model_save_dir'))
# 模型配置
model_2.prepare()
# 执行预测
result = model_2.predict(predict_dataset)
```
```python
from PIL import Image
import matplotlib.pyplot as plt
# 样本映射
LABEL_MAP = get('LABEL_MAP')
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(LABEL_MAP[predict_label]))
image_file, label = predict_dataset.data[idx]
image = Image.open(image_file)
plt.imshow(image)
plt.show()
# 随机取样本展示
indexs = [50,150 , 250, 350]
for idx in indexs:
predict_label = np.argmax(result[0][idx])
real_label = predict_dataset[idx][1]
show_img(real_label,predict_label )
print('样本ID:{}, 真实标签:{}, 预测值:{}'.format(idx, LABEL_MAP[real_label], LABEL_MAP[predict_label]))
```
## 4.3 模型的保存
```python
model_2.save('infer/MicroExpression', training=False)
```
# 5 基于Paddle-Lite进行安卓部署
## 5.1 PaddleLite简介
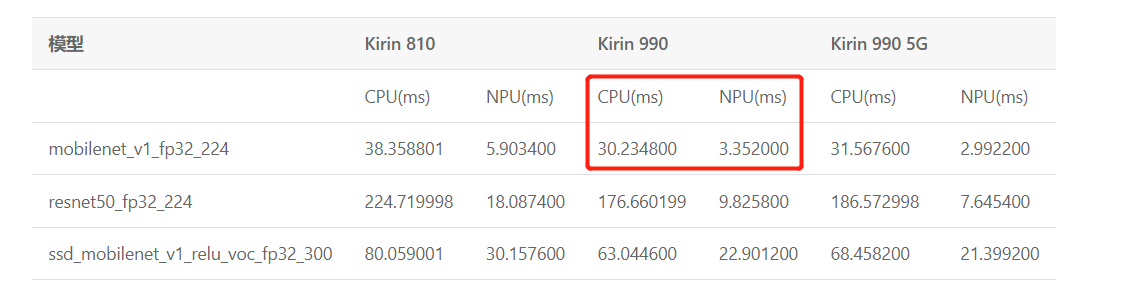
Paddle-Lite 是飞桨推出的一套功能完善、易用性强且性能卓越的轻量化推理引擎。 轻量化体现在使用较少比特数用于表示神经网络的权重和激活,能够大大降低模型的体积,解决终端设备存储空间有限的问题,推理性能也整体优于其他框架。本部分以本案例的微表情数据集的ResNet50模型为例,介绍怎样使用Paddle-Lite,在移动端(基于华为麒麟985npu的安卓开发平台)对进行模型速度评估。
华为麒麟NPU部署参考链接:
[https://paddlelite.paddlepaddle.org.cn/v2.10/demo_guides/huawei_kirin_npu.html](http://)
由下图可见,NPU上的运算速率是CPU的数倍:
说明:PaddleLite v2.10不支持鸿蒙系统下使用npu,若有需要,可按照上述链接改为EMUI系统。
## 5.2 准备工作
文件:infer文件夹中的 .pdmodel .pdiparams 和下载到本地的image_classification_demo文件,下载链接如下:
[https://github.com/PaddlePaddle/Paddle-Lite-Demo](http://)
工具:Android Studio、华为手机(开启USB调试模式)、USB数据线
Android Studio安装:
[https://blog.csdn.net/qq_41976613/article/details/91432304](http://)
通过以下命令,将.pdmodel 和 .pdiparams两个模型文件生成Android Studio可执行的.nb文件。
```python
# 准备PaddleLite依赖
!pip install paddlelite==2.10
```
```python
# 准备PaddleLite部署模型
#--valid_targets中参数(arm)用于传统手机,(huawei_kirin_npu,arm )用于华为带有npu处理器的手机
!paddle_lite_opt \
--model_file=infer/MicroExpression.pdmodel \
--param_file=infer/MicroExpression.pdiparams \
--optimize_out=./infer/ResNet \
--optimize_out_type=naive_buffer \
--valid_targets=huawei_kirin_npu,arm
```
### 5.2.1 配置文件_电脑端
* 在下载的Paddle-Lite-Demo进入以下目录,按下列步骤配置文件
Paddle-Lite-Demo-master\Paddle-Lite-Demo-master\PaddleLite-android-demo\image_classification_demo\app\src\main\assets
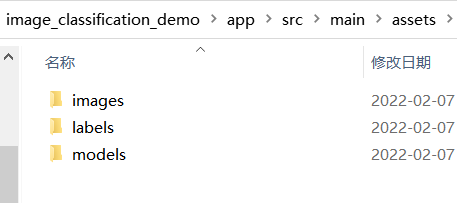 * 将待预测的图片放入ages文件夹
* 将待预测的图片放入ages文件夹
 * 将数据标签文件放入labels文件夹
制作标签文件见 classfication2/train.txt
**序号和类别的对应关系千万不能弄错了!**
* 将数据标签文件放入labels文件夹
制作标签文件见 classfication2/train.txt
**序号和类别的对应关系千万不能弄错了!**
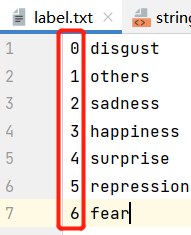 * 在models文件夹中放入自己的模型
创建子文件夹resnet_for_npu,将上述步骤生成的.nb文件下载到本地,并改名为model.nb
* 在models文件夹中放入自己的模型
创建子文件夹resnet_for_npu,将上述步骤生成的.nb文件下载到本地,并改名为model.nb
 ### 5.2.2 配置环境_手机端
1. 连续点击“版本号”以进入开发者模式
1. 开启USB调试按钮
1. USB配置选为PTP图片传输
## 5.3 完成部署
* 导入demo文件:
位置:Paddle-Lite-Demo-master\Paddle-Lite-Demo-master\PaddleLite-android-demo\image_classification_demo
* 在strings.xml文件中修改三行字符:在 models/ labels/ images/ 后修改为上文添加文件的名称。
### 5.2.2 配置环境_手机端
1. 连续点击“版本号”以进入开发者模式
1. 开启USB调试按钮
1. USB配置选为PTP图片传输
## 5.3 完成部署
* 导入demo文件:
位置:Paddle-Lite-Demo-master\Paddle-Lite-Demo-master\PaddleLite-android-demo\image_classification_demo
* 在strings.xml文件中修改三行字符:在 models/ labels/ images/ 后修改为上文添加文件的名称。
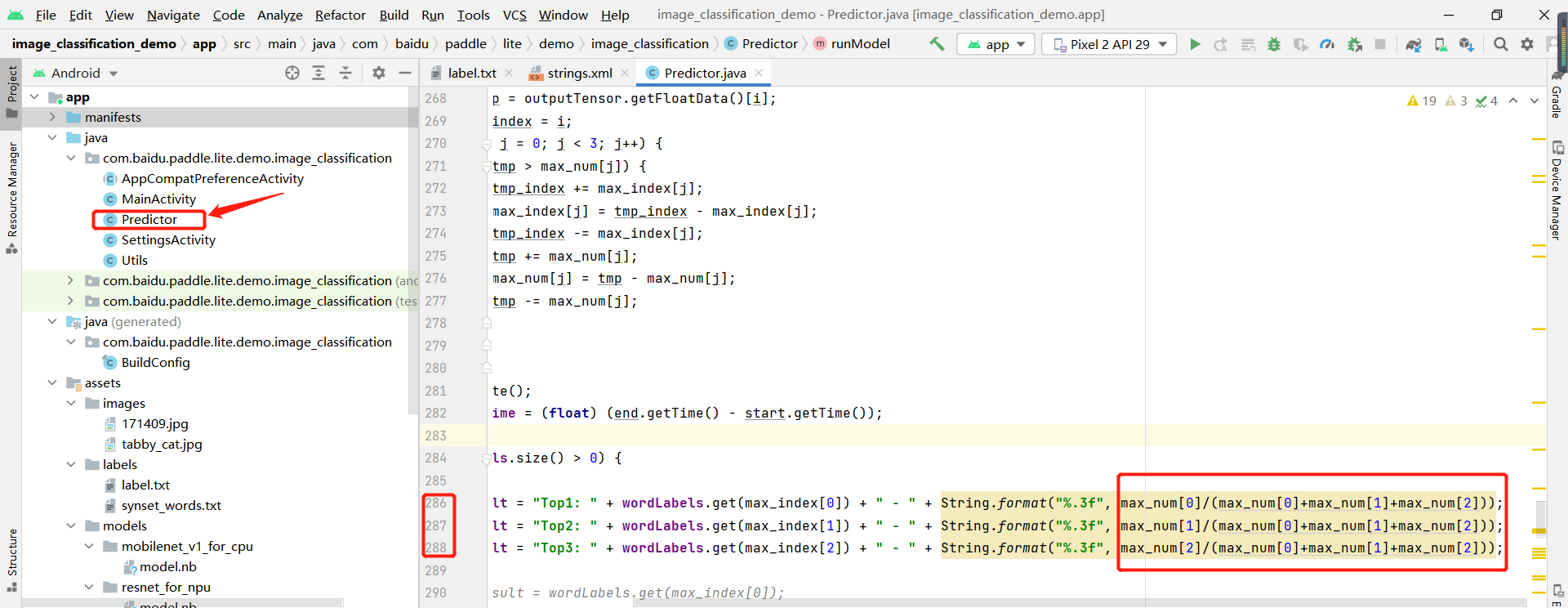
 * 在Predictor.java文件中修改三行代码,改为如下内容:
* 在Predictor.java文件中修改三行代码,改为如下内容:
 * 当Android Studio右上角设备信息为HUAWEI时,点击绿色三角形按钮下载至手机端:
* 当Android Studio右上角设备信息为HUAWEI时,点击绿色三角形按钮下载至手机端:
 ## 5.4 效果展示
手机会自动出现以下画面
Open Gallery可在本地相册中添加图片预测, Take Photo可调用手机摄像头进行拍摄预测, Settings可进行硬件性能的相关设置。
说明:由于我没有再把鸿蒙系统改为EMUI系统,故默认使用CPU进行预测,从预测时间几百ms可以看出,符合上文中官方给出的推理时间。
# 6 小结
* 现在基于ResNet50的微表情图片分类、部署的任务大致完成了,接下来打算通过引入光流算法对微表情视频文件进行分类,尽请期待;
* 感谢以上参考文档,为我提供解决问题的思路;
* 这是我在飞桨平台上的处女作,欢迎大家给我点赞,点Fork, 当然,有不足之处也同样欢迎读者朋友们给我指正,谢谢。
## 5.4 效果展示
手机会自动出现以下画面
Open Gallery可在本地相册中添加图片预测, Take Photo可调用手机摄像头进行拍摄预测, Settings可进行硬件性能的相关设置。
说明:由于我没有再把鸿蒙系统改为EMUI系统,故默认使用CPU进行预测,从预测时间几百ms可以看出,符合上文中官方给出的推理时间。
# 6 小结
* 现在基于ResNet50的微表情图片分类、部署的任务大致完成了,接下来打算通过引入光流算法对微表情视频文件进行分类,尽请期待;
* 感谢以上参考文档,为我提供解决问题的思路;
* 这是我在飞桨平台上的处女作,欢迎大家给我点赞,点Fork, 当然,有不足之处也同样欢迎读者朋友们给我指正,谢谢。